About FIN-X
The explainability of outcomes and processes in artificial intelligence (AI) applications is a crucial factor for trust among consumers and society — especially within the financial sector. In this project, we are developing tools to help internal users such as claims handlers and credit analysts interpret, evaluate, and communicate AI-driven outcomes. These professionals work directly with customers and must be able to explain decisions, particularly when outcomes like loan denials or fraud alerts are based on model predictions.
To explore what works—and what doesn’t—we created and tested explanations within a fictional but realistic use case: detecting potential car insurance fraud. Based on this scenario, we implemented designs for four common explanation types used in explainable AI systems: feature importance, counterfactuals, contrastive/similar examples, and rule-based explanations. Each format offers a different lens through which users can interpret a model’s decision, and we evaluated how well they score based on aspects such as understanding, trust, and actionability.
Explanation Types
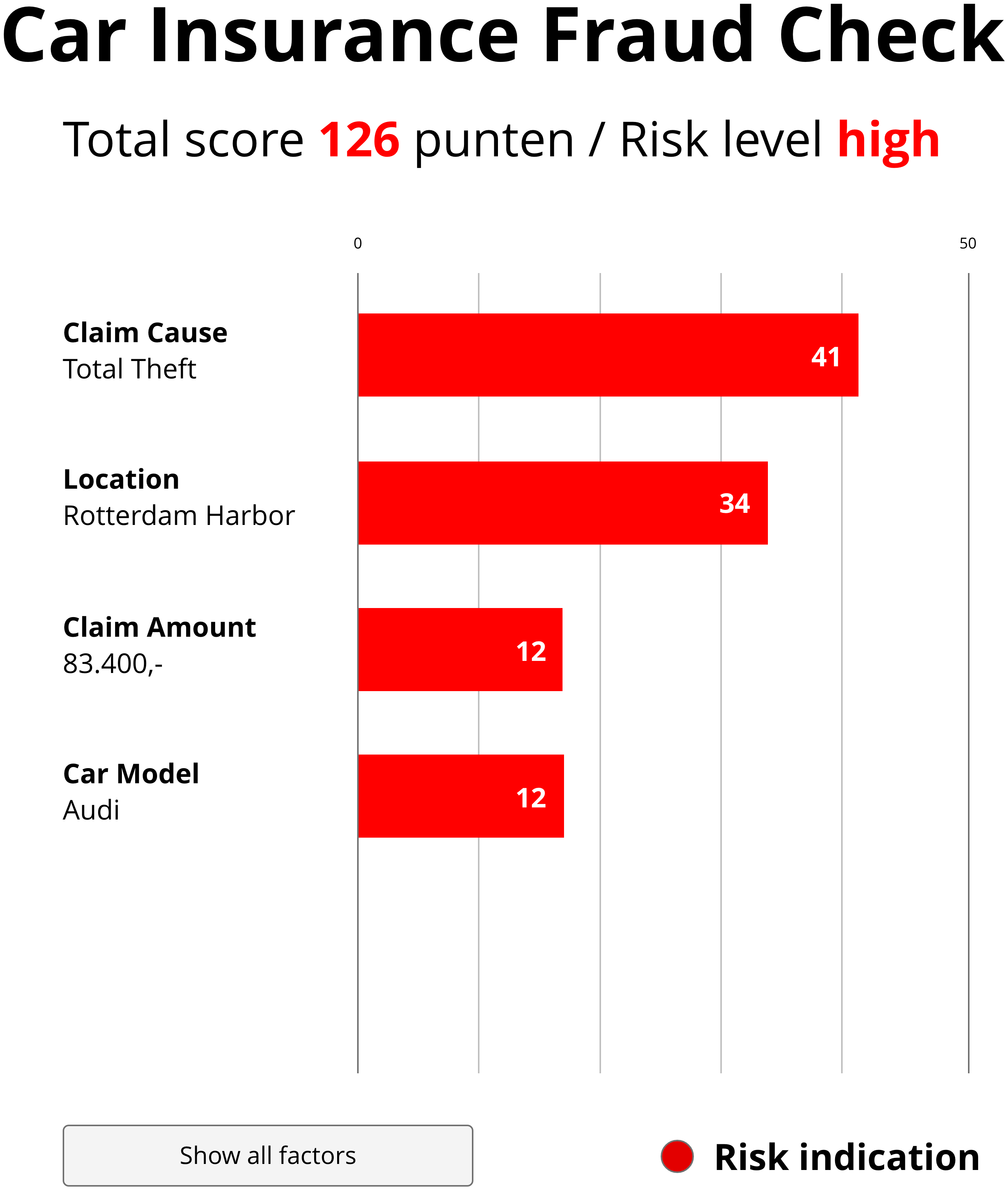
Feature Importance shows which input variables had the biggest influence on the model's decision. In the fraud detection case, this means showing which aspects of the claim—such as claim amount, claim timing, or prior claims—contributed most to the model labeling it as potentially fraudulent. This view helps users quickly identify “red flags” and assess whether the model’s reasoning aligns with their own.
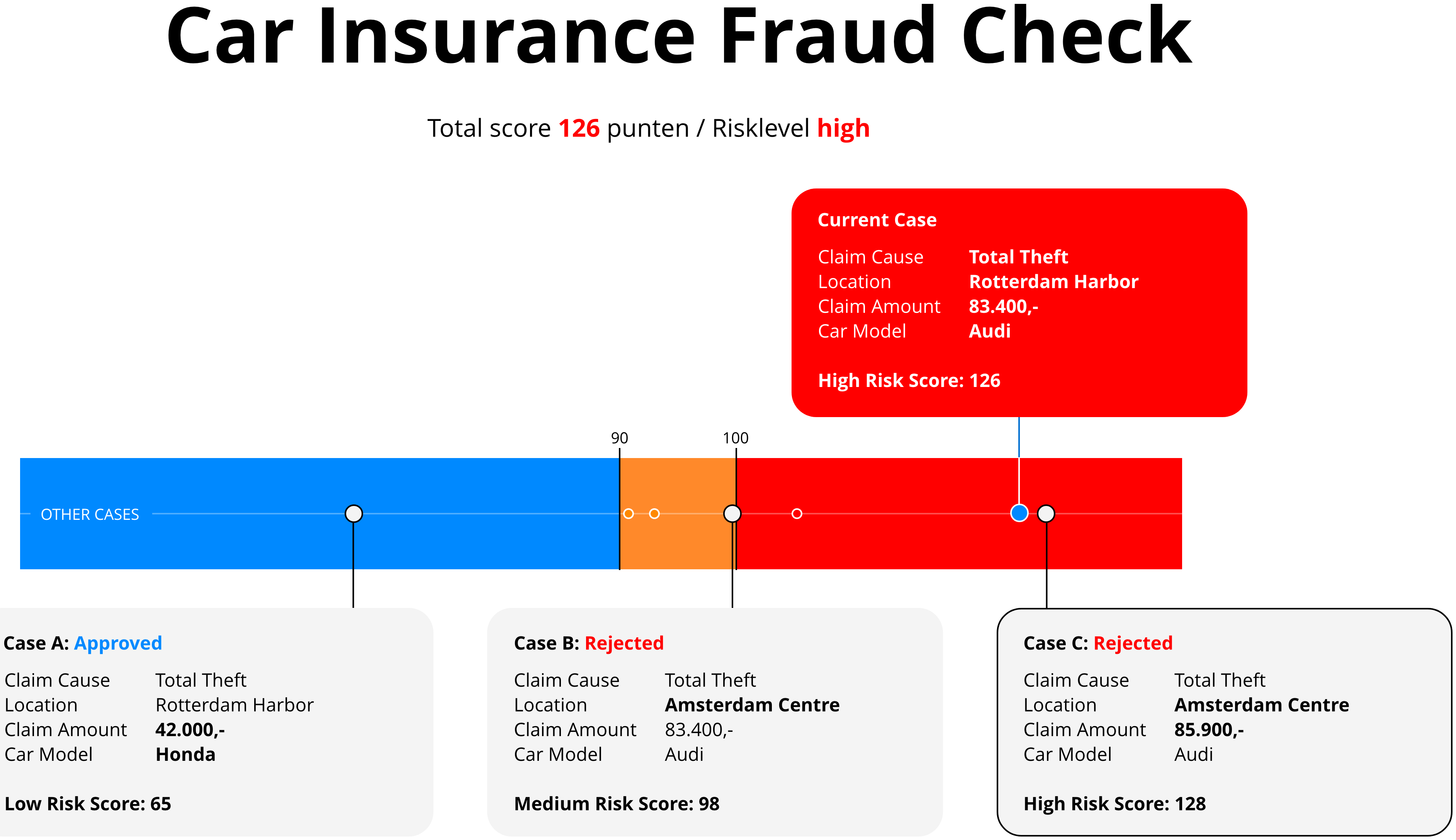
Contrastive and Similar Examples provide users with real-world reference points. Similar examples show previously processed claims that received the same prediction—for instance, other high-risk cases—so users can see consistency. Contrastive examples show similar claims with different outcomes, such as medium- or low-risk decisions, allowing users to spot what changed. This format leverages known decisions to help users validate the current case by comparison.
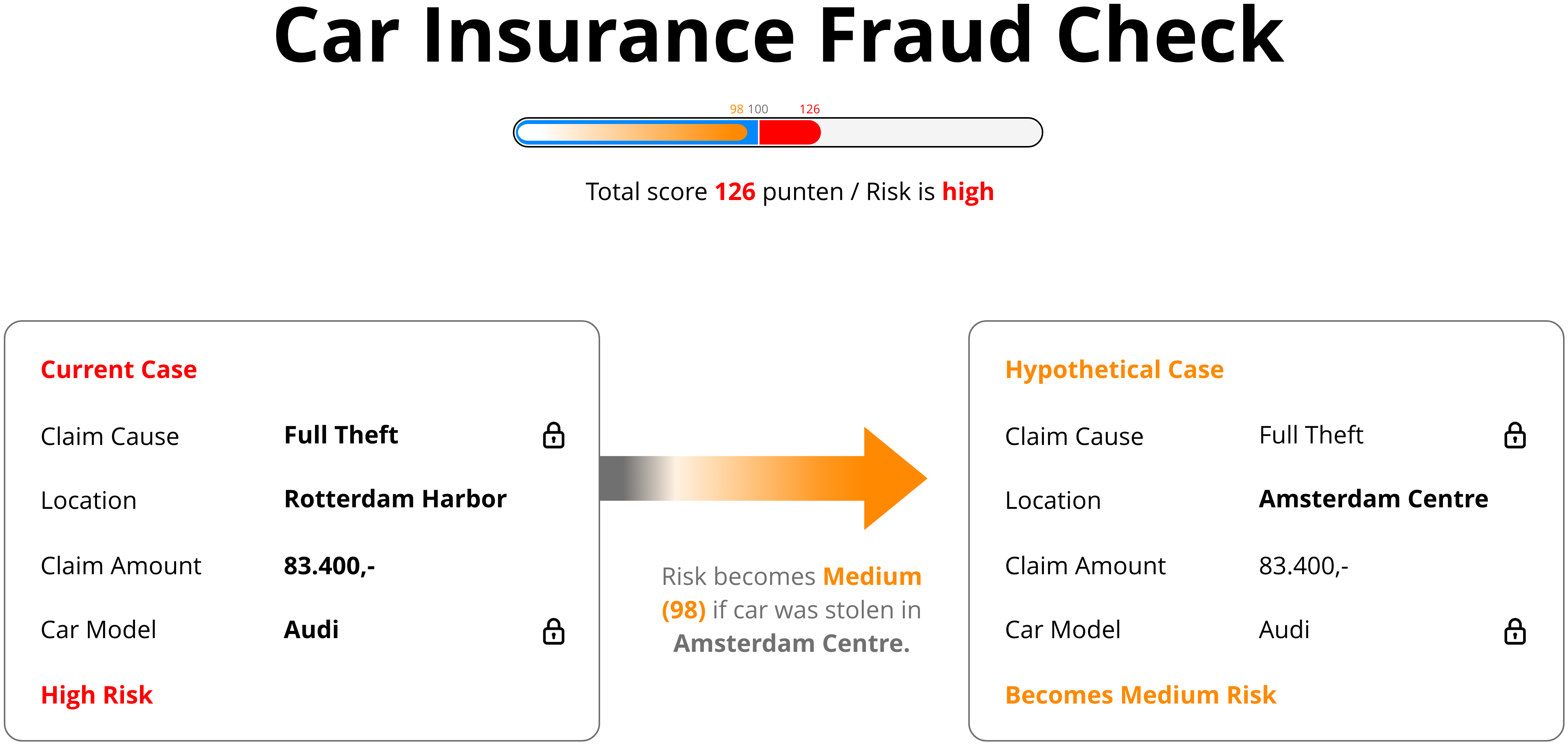
Counterfactuals explain what would need to change in order for the outcome to be different. For example, “If the claim amount were €2,000 lower, the model would not have flagged this as fraud.” These “what-if” scenarios make the model’s decision boundary more transparent and help users understand the logic behind the classification.
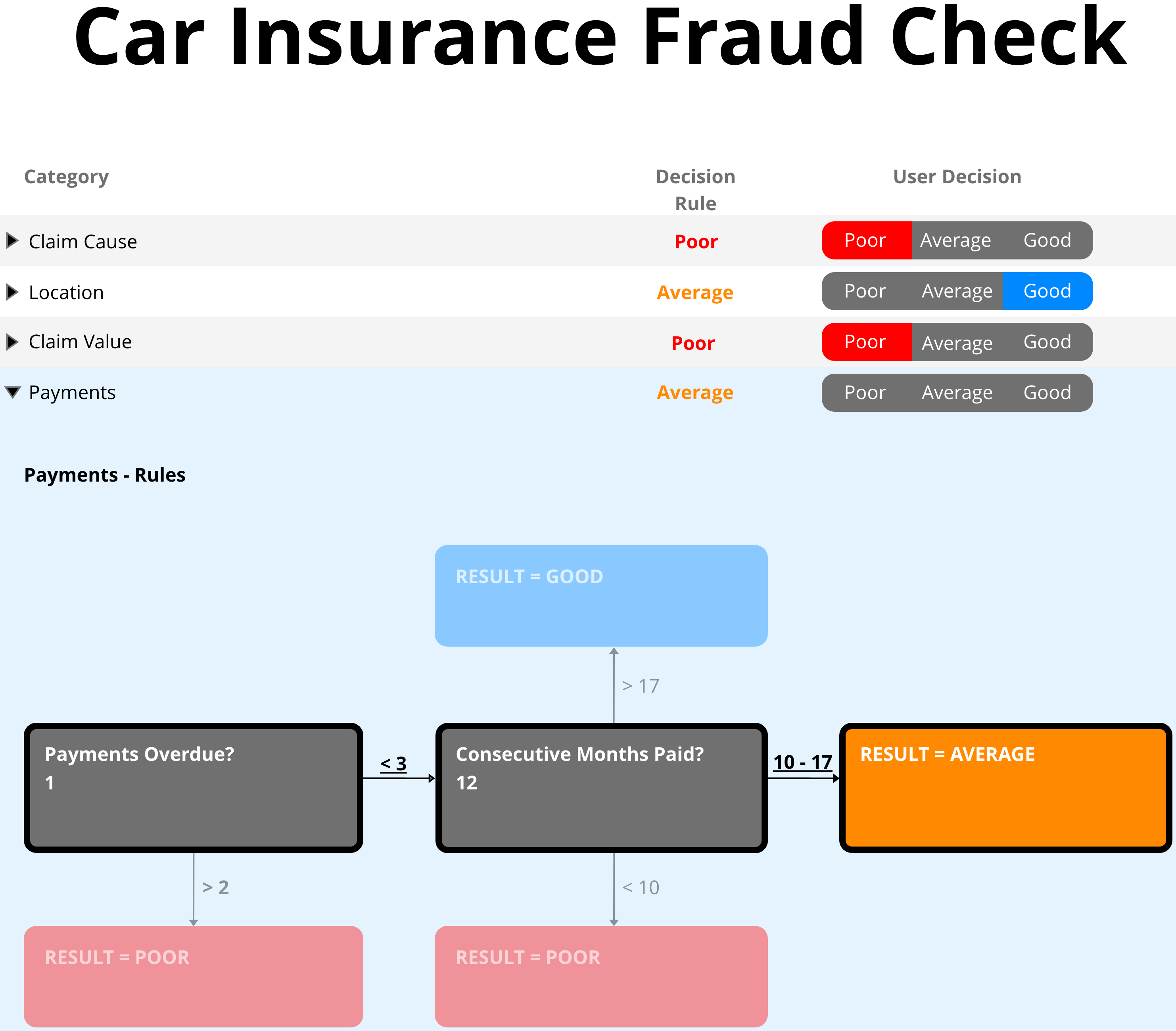
Rule-based Explanations present the logic behind the decision in either plain-language rules or tree-like structures. These explanations are closer to how human experts reason: “If the claim amount is above €10,000 and submitted within 3 days of the incident, then mark as high risk.” Rule-based formats are helpful when users need traceability and a consistent rationale.
Objective
The project aims to make a tangible contribution to the development of human-centered AI by providing tools that give internal users better insight into how AI systems function—and how their outcomes can be interpreted and acted upon.
Results
The project delivers practical guidelines in the form of tools and design patterns. These support the generation, communication, and evaluation of explanations. Our main audience includes designers, developers, and product teams building AI and explainable AI systems in high-stakes environments.
Explanation Criteria for User Feedback
We evaluate the quality of explanations based on user-centered criteria. These were derived from interviews, workshops, and design evaluations conducted with internal users:
- Understandability: "Is the explanation easy to understand?"
- Ease of Understanding: "How easy is it to understand the explanation?"
- Ease of Use: "How easy is it to interact with or navigate through the explanation?"
- Satisfaction: "How satisfying is the explanation?"
- Usefulness: "How useful is the explanation in understanding the prediction?"
- Trust: "How much can you trust the explanation?"
- Typicality: "Does the explanation resemble what you would typically see for similar predictions?"
- Sufficiency: "Does the explanation provide all the information you need?"
- Correctness: "Is the explanation correct and consistent with the prediction?"
- Compactness: "Is the explanation clear and concise, without unnecessary details?"
- Actionability: "How helpful is the explanation in guiding what to do next?"